Digital Collections, Crawling, and Aggregating Content
Published: 2012-02-08 00:18:00 -0500
Code4Lib 2012 Lightning Talk That Wasn’t
Lightning talks filled up fast this year at Code4Lib before I had a chance to sign up, which is probably for the best since I had already had the opportunity to give a full length talk. Here is the lightning talk that I had prepared with each slide being followed by my draft speaker notes.

Hi.

Digital Libraries have aspired to create the one big pot of digital library stuff to hold everything. For the most part we’ve used niche protocols, dumbed-down metadata, cumbersome workflows, and lots of time massaging metadata in an effort to achieve these big aggregations.
I want to talk about what I think is better way to do aggregations. There’s a lot more you can build with what I’m talking about, but I want to set aggregations in my sights.
What if we start with the existing distributed collections on the open web? Instead of using niche protocols and metadata formats we used web pages as source materials. Collections are already producing Web pages, so why ask them to maintain something else too just for your aggregation?
Then we could crawl those pages. But we can’t crawl the whole web, so how do we figure out what to crawl?
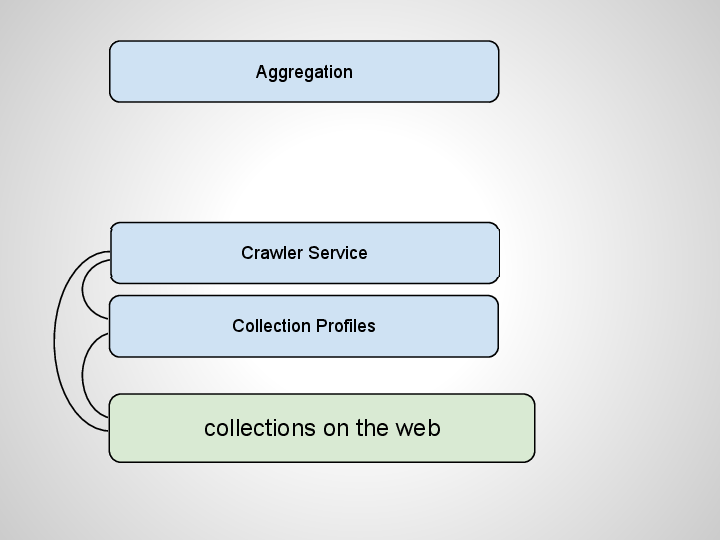
We curate profiles for digital collections, like LinkedIn profiles. A minimal profile for a digital collection could be a name and a URL.
There’s a lot more you could do with collection profiles, and I’ve written about some of those with Tito Sierra. But right now let’s stick to how they enable crawling. Once you know what URLs exist you can constrain your crawling to just those trusted domains. A lot less work for the crawlers.
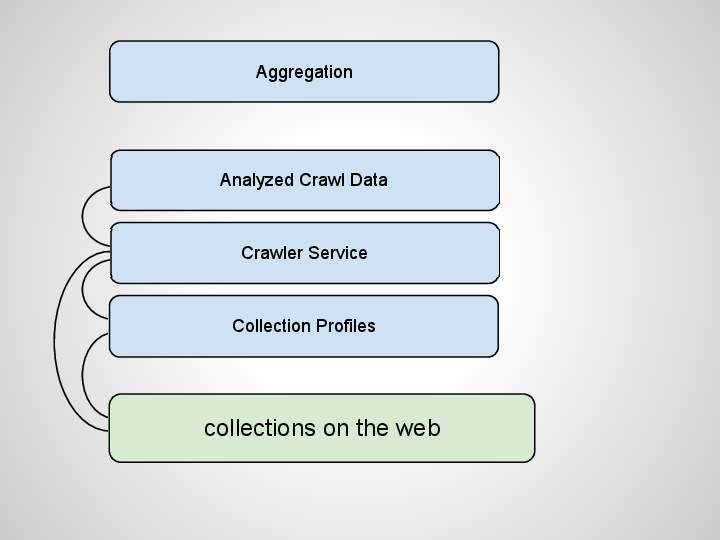
OK, now we’re able to crawl just part of the web and have the pages. We’ll want to do some processing on them to extract content and index. Some natural language processing can be done on the apge. You can also pull out structured data like RDFa, Microformats, or Microdata from the pages. Since all of the collections have profiles, we can trust the data on the page.
You could also fetch images and other linked assets for thumbnails.
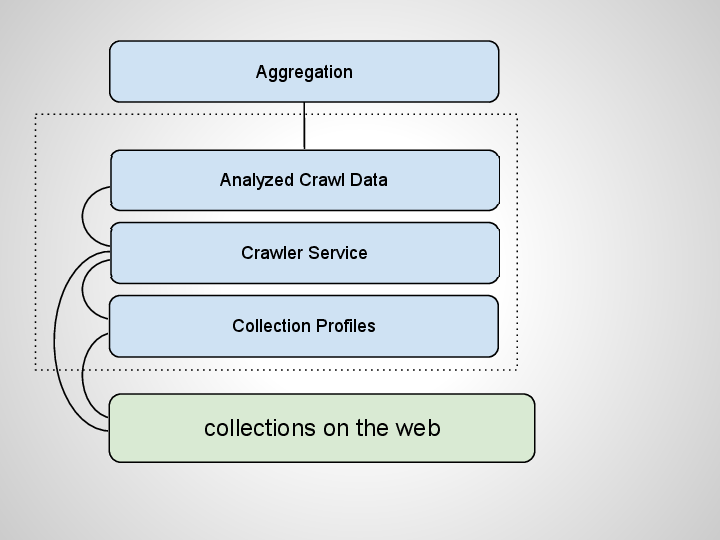
On top of this data you can start to create any number of virtual aggregations.
Now even this architecture could be rather expensive to generate all this crawl data.
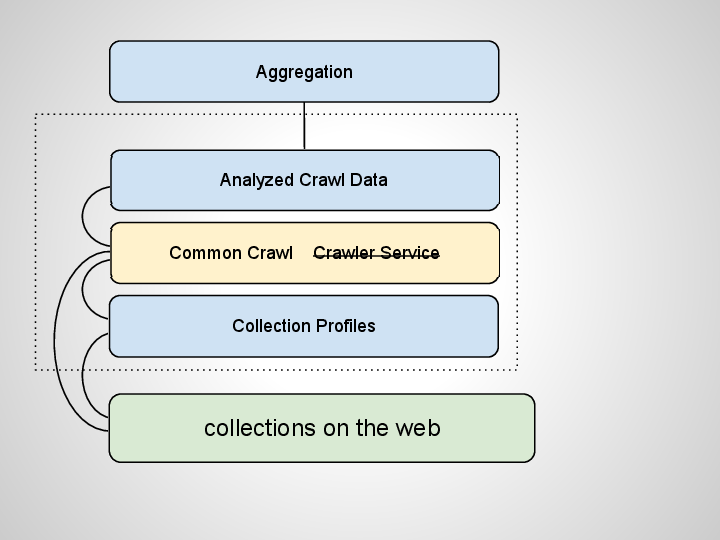
Common Crawl is a relatively new effort to crawl the quality web and make the crawl data available for free. It does cost a bit to access the Amazon buckets. But it is possible to run Hadoop Map/Reduce jobs over the corpus to extract what part you’re interested in. This could be significatly cheaper than crawling the web yourself. You could eventually use an API to process only those parts of the corpus which contain pages from the sites you’re interested in.
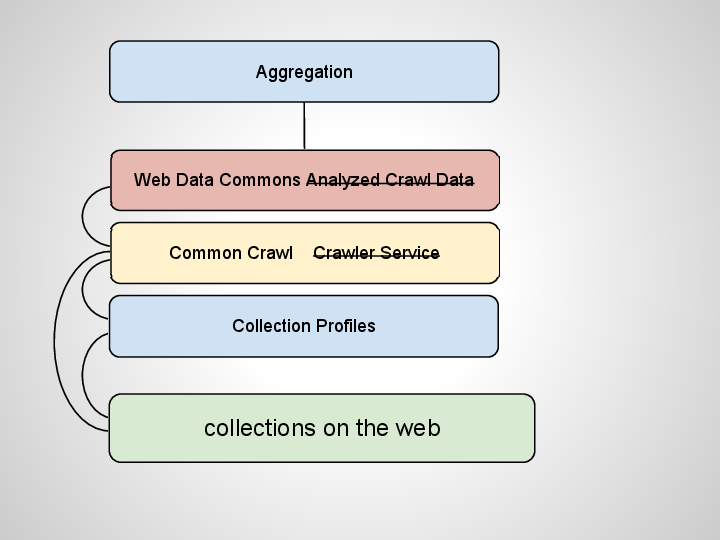
Web Data Commons is a new effort to use the Common Crawl corpus to extract structured data like RDFa, Microformats, and Microdata. They plan on making this web data available for free download.
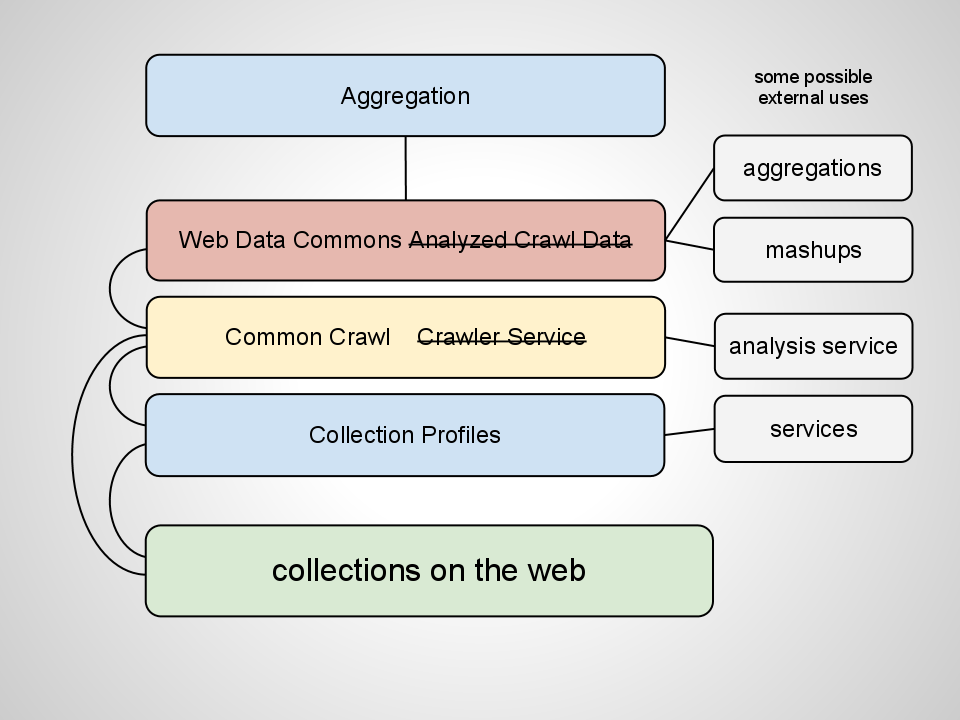
So it is beginning to be possible to create digital library aggregations (and lots of other services) at scale at very low cost using a web-centric approach. Small startups and individuals will soon be able to create their own aggregations or services around this common infrastructure at very low cost.
What’s nice about this approach is that anything you ask a digital collections site to do could benefit the collection more generally on the open web. Sitemaps are good and the search engines use those too.
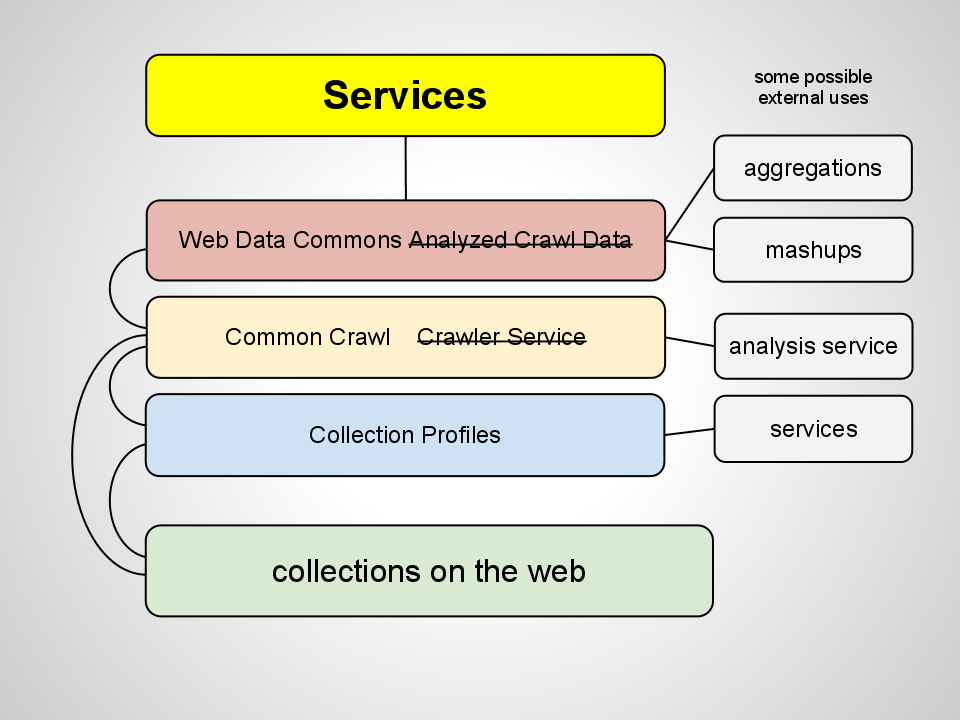
And once we’re to this point the need for a huge aggregation kind of drifts away. Small aggregations may have a place but otherwise discovery happens through search engines. With all of this digital collections data available it becomes possible to stop thinking in terms of aggregations and to think instead of value-added services for collections.

Here are some next steps to get us closer to this approach working.
Get Crawled. I’ve made contact with Common Crawl and have raised the issue about getting cultural heritage sites crawled.
Use Microdata. I’ve written about using Microdata and Schema.org. Let’s talk more about this.
Build a Collection Profiles System. I’ve got lots of ideas and some code started. I would like some help and support to get it going further.

Please get in touch with me if you’re interested in this approach. I’d be interested in a breakout session about aggregations, crawling, and big web data. Please let me know if you’re interested in talking more about this.